Adding Google Custom Search to a headless Ghost blog with a React/Redux frontend

- 11 min read
The Portland Pour is a headless Ghost blog with a React/Redux front end. We chose this architecture for several reasons, including planned growth which includes other services like an online store, news and event aggregation, and workshop promotion. Our desire for a fully decoupled front end, which would allow us freedom of choice and change on any of our back end or external services was important to us, as was the need for content related components which we could use on other projects consistent with our style guide.
The simplicity of Ghost, and the super easy Content API, along with its scalability, speed, and ability to host on our servers made it the winner, in spite of the lack of search. Lack of search as a core feature would have otherwise been a deal breaker, but all the other platform options fell short on other counts, and we really like Ghost exactly because of its basic feature set, so we chose it knowing that we would have to deal with search in some way or another.
We began by surveying existing solutions for Ghost, of which there are several, but the downside they share is that they are all client side. There is some virtue in client side search and indexing, it allows for speed, typeahead, and some nice things, but for it to work it needs all the content from Ghost on the client. For a smaller site, or a blog that only updates once in a while, this wouldn’t be a problem and would be a good option, but there’s a point where it seems inefficient to download all the content just for search, and in our case it just wasn’t a reasonable solution.
We considered hosting our own search engine. Elasticsearch is an excellent product, as are other choices like Solr, but their vast feature sets are much more than we need, and the installation and technical attention required by a stand alone search engine, again, wasn’t a reasonable solution.
We chose a simple blog because we want the simplicity that empowers us to just write and post without distraction, and maintaining a search engine is a distraction. Google, in my opinion, is a good search engine, someone else maintains it so we don’t have to, there’s a reasonable UI to set up and configure Custom Search, and they offer a REST API. If we can get the results as a JSON response, we can request only what we need from Ghost. Therefore, we chose Google Custom Search for our search engine.
Setting up Google Custom Search
Before you can set up and use Google Custom Search (CSE), you’ll need a GSuite account with CSE enabled. If you have a GSuite account, and admin access, you can enable Google Custom Search in the Admin panel at Apps > Additional Google Services.
Once CSE is enabled, you can create a new search engine. Visit https://cse.google.com/cse/all and sign in with your GSuite credentials, and add a new search engine.
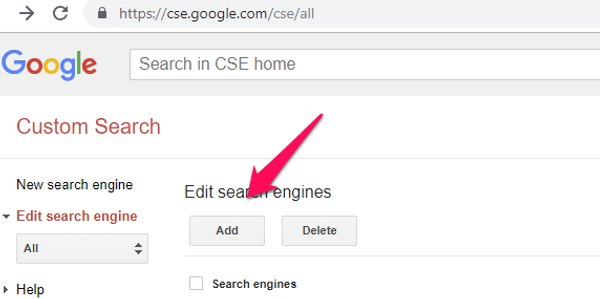
Now enter the domain(s) you’d like to search. In our case, we only want to search blog posts, so we use the URL to our posts. Remember, the URLs for us are controlled by React Router, not Ghost, so we use the public URLs from our React front end.
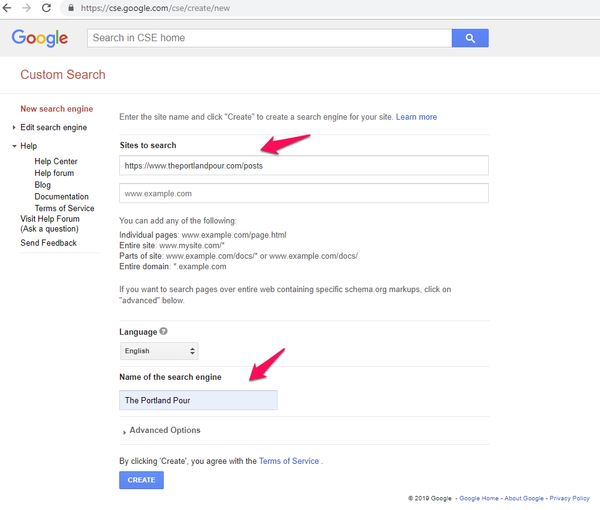
Your new custom search engine is now ready and will appear in your list of search engines. Click on it to open the detail view and note the search engine ID.
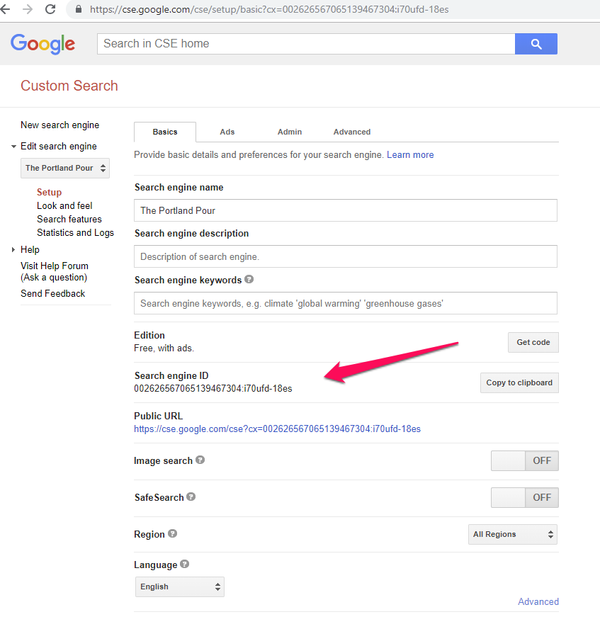
Next, set up the API. When you make a CSE, a JSON API is available, but you need an API key. To get an API key, click on the Get started button at the bottom of the CSE detail screen. You’ll want to select the Custom Search JSON API. You can also navigate directly to https://developers.google.com/custom-search/v1/introduction because that’s where the button takes you.
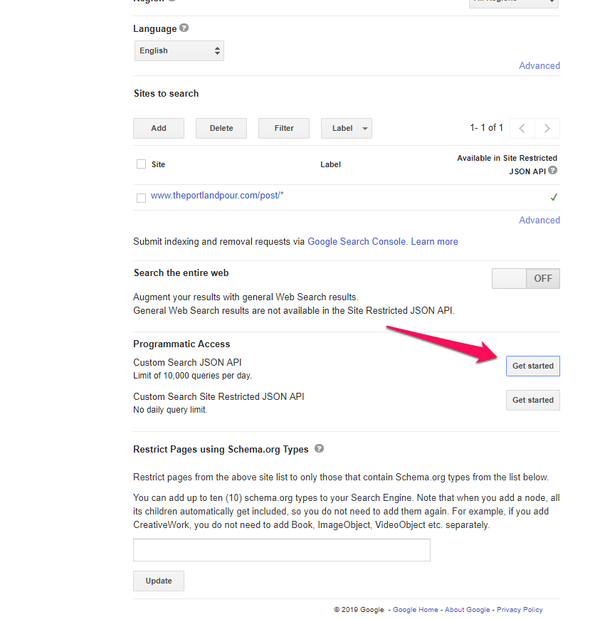
Once there, click GET A KEY
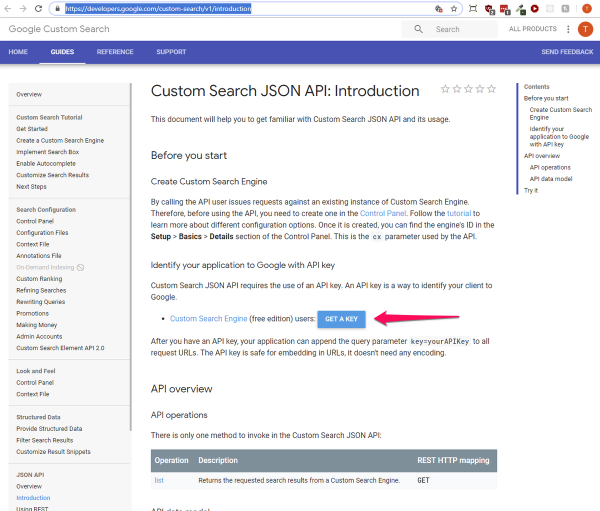
A dialog will open, select the search engine you created before, and a key will be generated for you. Note this key because you will need it to access the API.
Using Google Custom Search in a React app
The CSE API has only one endpoint, list. You may have noticed, when setting up the search engine, that there are 2 variants of the API, the CSE API, and the CSE site restricted API. The CSE API limits requests to 10,000 per day, but you get unlimited sites to search. The CSE site restricted API only lets you search within one domain, but you get unlimited requests. Whichever you choose is based on your situation, but the list endpoint is the same for both. You can find documentation, and a sandbox, at https://developers.google.com/custom-search/v1/cse/list
An API request to the list endpoint requires three things:
- **q **— the search query
- cx — the search engine ID
- key — your API key
There’s also an extensive list of additional parameters to shape your request as you see fit. For this exercise, we’ll be using the three required parameters, plus num, number of search results to return, and start, the index of the first return result. The latter allows for paging through large result sets. The API only returns up to 10 results at a time, but, as you’ll see, we request 9 at a time so we can lay our results view out in a grid, like our other list views.
Request the results from the API as you would in your React app. In our case, The Portland Pour is a hybrid app. The first view is rendered on the server using Express, and all subsequent views are handled on the client. React Frontload, a library that asynchronously requests data on either server or client is used for both, and Redux is used for state. That said, you can request from the CSE API using your pattern of choice. It’s just a REST API, so have at it, but this is how we do it.
We also use views as one would controllers in an MVC architecture, and our components are stateless. Search, then, is a view that manages the activity required to request search results from Google, and request content from Ghost. This means you can use the search bar, or go directly to a search URL.
The route to the search view looks like this, where q is the search term, and **page **is the page within the search results used to figure out the start parameter of the CSE API request:
<Route path="/search/:q/:page" component={SearchView} />
To search, a search term is entered into the search form presented by the SearchBar component

We use local state to control the form input, then, when either the search button, or enter key is clicked or depressed, navigate to the search view by calling the search method on click (or enter).
search = () => {
if(this.state.q.length) {
this.props.history.push('/search/' + this.state.q + '/1');
}
}
Notice in the example that we pass the value of the input (this.state.q) and 1 for the page, since this is a new search, as route match params.
React router navigates to the search view, and passes the params. In the search view, React Frontload handles the request. Here is the Frontload method. We’ll step through it line by line and look at the actions and reducers and how they work, but, here it is in full.
const frontload = async props => {
await props.dispatch(blogActions.waiting());
await props.dispatch(blogActions.clearPosts());
const q = props.match.params.q;
const start = ((props.match.params.page - 1) * 9) + 1;
const req = 'q=' + q + '&num=9&start=' + start;
const search = await blogActions.search(req);
await props.dispatch(search);
if(search.data.slugs.length) {
const query = {filter: 'slug:[' + search.data.slugs.toString() + ']'}
const posts = await blogActions.fetchPosts(query);
await props.dispatch(posts);
}
};
First things first, we dispatch a waiting action to load an animation for the user to see while the work is done. The animation isn’t always seen, both the CSE API and Ghost Content API are pretty snappy, but, you never know, so load that animation.
Next, clear out any existing posts in state. We use a single list component which lists whatever is in the Redux posts collection, so we want it empty. Otherwise, there would be a flash of previous content, and that’s looks bad.
The parameters we need, q and start are next. The first, q, is the search string, so we assign it to a constant, but start we have to figure out. Our app uses the concept of pages, as does the Ghost Content API, but the CSE API uses item count, so we have to translate our page to the CSE starting item. We know we request 9 items from the CSE API, so a little math is used to figure out what the start parameter should be.
This little bit of the request is concatenated, line 6, and an action to make the request is called on line 7. Let’s look at the action. BTW, if you’re following along with our gists, note that they are named medium-… because they are being used in a Medium post. It helps me stay organized.
const success = (type, data) => { return { type: type, data: data }};
const fail = error => { return { type: blogConstants.ERROR, error: error };
const search = (q) => {
const endpoint = searchHelper.getEndpoint(q);
return new Promise((resolve, reject) => {
API.get(endpoint)
.then(
search => {
const data = {};
data.raw = search;
data.q = search.queries.request[0].searchTerms;
data.slugs = search.items ? search.items.filter(item => {
return item.link.includes('post');
}).map(item => {
const link = item.link.replace(/\/$/, '');
return link.split('/').pop();
}) : [];
resolve(success(blogConstants.SEARCH, data));
},
error => {
reject(fail(error));
}
);
});
}
Stepping through it, line 5 is where we prepare the endpoint. The helper method looks like this:
import config from '../config';
const getEndpoint = (req) => {
const { cx, path } = config.search.api;
return path + `?key=${process.env.REACT_APP_API_KEY_SEARCH}&cx=${cx}&${req}`;
}
Notice that we store the path to the endpoint, https://www.googleapis.com/customsearch/v1, and our search engine ID in our app’s config (line 4) but the API key is kept on the server in a .env file for security. This is a cool thing about React. If you put data in a .env file at the root of your Node server, and preface it with REACT_APP_ it will be available on the client in process.env.
Now that we have an endpoint, let’s get back to our action and see how the request is made (medium-search-action.js above, line 11). The API.get method is this:
function get(endpoint, options = {}) {
return fetch(endpoint, options).then(response => {
return response.ok ? response.json() : Promise.reject(response.statusText);
}).then(data => {
return data;
});
}
Once we have the response, the data can be parsed. If we look at the response from the CSE API, it looks like this:
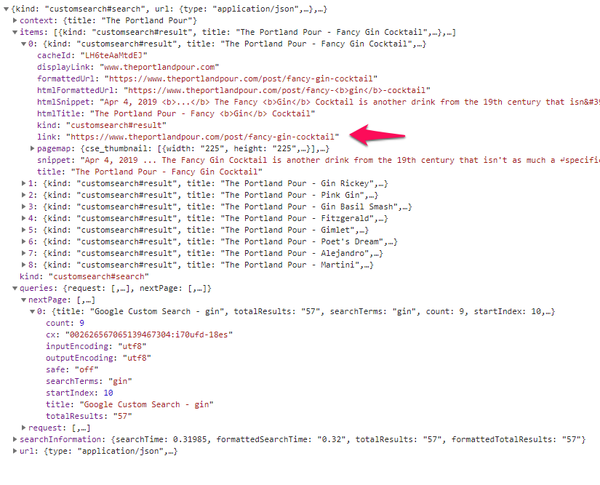
There is alot of information, but what we want is the items collection, and will be parsing the link for each item. You can see this starting in the action gist above, on line 17. While we know we are only searching post views from our app, we filter just to be safe and look only for links that contain post. What we want from those links is the last part, the part after post/ which is the post slug.
Another thing we know is that we index URLs in Google with no trailing slash, but we also assume that Google may have them with trailing slashes, too. So, to be safe, as seen beginning on line 19 of the action gist, we drop a trailing slash from the link, if it’s there, then split the link on the slashes, and pop the last item from the array. After we map all the items, the result is an array of slugs, which is dispatched using the success method, shown on line 1 of the action gist.
Search results and Ghost
Remember that Frontload method where all this started? Let’s look at that again, and see how we can get our content from Ghost.
const frontload = async props => {
await props.dispatch(blogActions.waiting());
await props.dispatch(blogActions.clearPosts());
const q = props.match.params.q;
const start = ((props.match.params.page - 1) * 9) + 1;
const req = 'q=' + q + '&num=9&start=' + start;
const search = await blogActions.search(req);
await props.dispatch(search);
if(search.data.slugs.length) {
const query = {filter: 'slug:[' + search.data.slugs.toString() + ']'}
const posts = await blogActions.fetchPosts(query);
await props.dispatch(posts);
}
};
Line 9 is where we do the same thing we did to make a request to the CSE API, only this time we’re making a request to the Ghost Content API. Before we do, check to make sure that there are slugs to request. There may not be. If we were on the last page of the search, or we made a request to the CSE API and got no items, we can skip making a request to the Ghost Content API.
If, however, we do have an array of slugs, we can request those posts. The Ghost Content API query is prepared on line 10 according to the Content API documentation at https://docs.ghost.org/api/content/. Specifically, we’re concerned with filtering, https://docs.ghost.org/api/content/#filtering. If we use the filter parameter, and pass an array of slugs, as a comma delimited string in our query, we’ll get those posts in the response.
filter=slug:[fancy-gin-cocktail,gin-rickey,pink-gin,gin-basil-smash,fitzgerald]
We can then pass this query to our action, fetchPosts.
const success = (type, data) => { return { type: type, data: data }};
const fail = error => { return { type: blogConstants.ERROR, error: error }};
const fetchPosts = (opts = {}) => {
const options = Object.assign(
{},
{
filter: 'featured:false',
include: 'authors,tags',
limit: 9,
order: 'published_at%20DESC'
},
opts
);
const queryString = Object.keys(options).map(key => key + '=' + options[key]).join('&');
const endpoint = blogHelper.getEndpoint('posts', queryString);
return new Promise((resolve, reject) => {
API.get(endpoint)
.then(
posts => {
resolve(success(blogConstants.GET_POSTS, posts));
},
error => {
reject(fail(error));
}
);
});
}
view raw
Our app uses this method any time it needs to fetch posts from the Content API, so, as you can observe on line 5, we have a few default parameters. When we pass parameters to this method, if we pass parameters to this method, they will be used instead, or in addition to, the defaults. The only parameter we pass in this case is the filter. The others are good. Notice how we request the posts in date order (line 13) because we always want our results in the order in which they were published, newest first, for any given page, regardless of the order CSE thinks they should be in. They will be generally relevant by page, but your case may require more refined ordering, or the order in which Google wants, so adjust accordingly.
From this options object, the query is created, as shown on line 17, and the endpoint prepared with a similar, but not entirely the same, method as before. You can compare to the getEndpoint method above, which is a bit different because of the requirements of two different APIs.
import config from '../config';
const getEndpoint = (endpoint, query='', slug='') => {
let ret = config.blog.host;
ret += '/';
ret += config.blog.api.path;
ret += '/';
ret += config.blog.api.endpoints[endpoint];
ret += slug ? '/' + slug : '/';
ret += '?';
ret += 'key=' + process.env.REACT_APP_API_KEY_BLOG;
ret += query ? '&' + query : '';
return ret;
}
As before, we keep the standard stuff in config (path and list of possible endpoints) and the API key in a .env file on the server. The rest is concatenation.
The request to the Content API is made using the same API.get method we used to request search results from the CSE API above. We pass the response, our list of posts, back to the Frontload method, which, as seen in the frontload-search-example gist above, on line 10, is dispatched to Redux. Redux then disables the loading animation, causes a render, and the search results, our collection of 9 posts, is displayed using the same component as any other list of posts in our app.
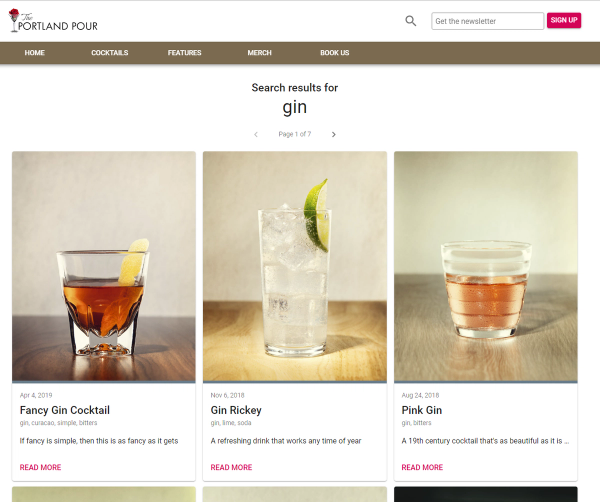
Summary
An examination of patterns and methods such as this may look complex at first, but it really isn’t. If you were able to follow along, you can see all that we are doing is requesting a list of 9 items from one API, and then using those items to request the same 9 items from another API. What looks like complexity really is just a desire to reuse as much code as we can, and stay DRY.
Is this approach inefficient? Two API requests for one set of data? Yes and no. On the one hand, both APIs are very fast, and we’re only requesting 9 items, regardless of how large the search results may or may not be. On the other hand, it’s still two API requests for one set of data.
The alternative, however, is not nice. We could have used the CSE URL and an iframe to embed search on our blog, but then the search results would be an entire HTML payload rendered in a style that is not ours, with results that are different than how we present our content lists everywhere else. Iframes, in my opinion, are so very 2007 (OK, iframes still have value, and YMMV, but REST APIs are a better choice in some cases and for some projects, such as ours), and there are better ways to do things, even if they require two requests for one set of data.
We totally prefer the option that gives us the freedom to present search results as we want them, and we feel it’s a fair price to pay for our users, who see lists of posts in the same way in every context. You may disagree, or have different ways of achieving the same ends, but this is what works for The Portland Pour.